Research staff:
In extreme-scale, high-performance computing systems (HPC), system-wide failures take a non-negligible amount of time to propagate from one part of the system to another. Similarly, the recovery mechanisms, like the failovers in the network and in the file system, require a non-negligible time to complete. The common assumption that failures during recovery are low-probability events—to be ignored when addressing resiliency at large scale—thus does not hold; the system is indeed susceptible to additional errors that can occur during recovery. This finding has motivated research on methods to intercept and contain the propagation of errors before they impact the applications and the system itself. The goals of this research are:
- To use large volumes of monitoring data (e.g., performance, environmental, and system error logs) to measure and analyze the propagation of errors in the system, and their impact on applications.
- To recreate controlled failure scenarios through fault injection experiments on real systems.
- To design fault-aware resiliency mechanisms by using data-driven methods for interception and containment of errors, such that errors have minimal impact on applications.
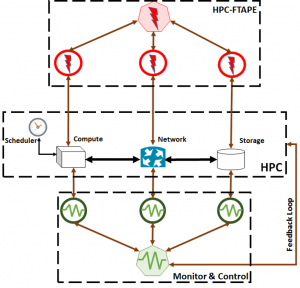
Fault injection is performed on Cray systems using built-in administrative commands (Figure). For example, some of the commands allow us to modify the values in memory to recreate failures in controlled conditions. Once the experiments are executed, we collect all the logs (e.g., system logs, performance logs) and analyze them. The experiments are used to characterize the fault tolerance of the Cray systems in different failure scenarios and with different workloads. The analysis is also addressing the characterization of the impact of failures on user applications.