Research staff:
We address the challenge of integrating support for reliability and security in a single framework in the context of cloud computing. This is a challenging task since security and reliability problems are apparently dissimilar, and require to cope with (detect and recover from) different classes of failure conditions. We have developed methods that combine continuous monitoring and hardware architectural invariants, to provide a foundation for design and implementation of low-overhead, and highly efficient resiliency mechanisms for the current generation of large virtualized computing systems.

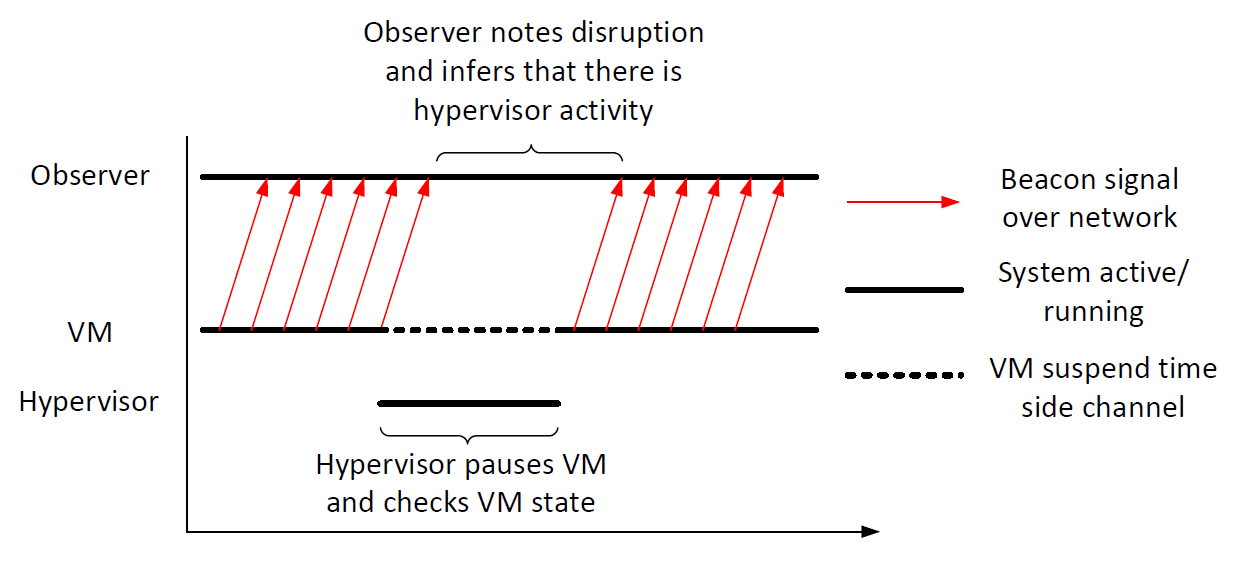
Our methodology consists in placing monitoring software at the hypervisor level (Fig. 1), and taking advantage of hardware-assisted virtualization. We bridge security and reliability qualities to the cloud computing, with the ultimate goal of providing them as a service to cloud users. In virtualized environments, it is often assumed that hypervisor activity is hidden from guest VMs, but we are looking into ways that information about the hypervisor can leak to a guest VM. For example, an attacker may be able to link interruptions in VM network activity with a hypervisor-level monitoring system, because the monitoring system needs to pause the VM to check the VM state (Fig. 2). Identifying where and what kind of information is leaked will help secure VMs and prevent clever attackers from obtaining sensitive data from cloud-based systems.
Formal Validation of Cloud Computing.
Our research is considering a formal approach to virtual machine monitoring. We seek to formalize the virtual machine monitoring techniques described above by using linear temporal logic (LTL). By modeling the guest environment and hypervisor as state transition systems, we can apply methods such as state-space searches and model checking to verify the proposed VM monitoring techniques. We execute our models using Maude, a high-performance logical framework based on rewriting logic.